
P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting
Published:
Author: Sungwon Kim, Kevin J. Shih, Rohan Badlani, João Felipe Santos, Evelina Bhakturina, Mikyas Desta, Rafael Valle, Sungroh Yoon, Bryan Catanzaro
Posted: Sungwon Kim
Overview
In our latest work, we present P-Flow, a fast and data-efficient zero-shot TTS model that uses speech prompts for speaker adaptation. P-Flow comprises a speech-prompted text encoder for speaker adaptation and a flow matching generative decoder for high-quality and fast speech synthesis. Our speech-prompted text encoder uses speech prompts and text input to generate speaker-conditional text representation. The flow matching generative decoder uses the speaker-conditional output to synthesize high-quality personalized speech significantly faster than in real-time. Unlike the neural codec language models, we specifically train P-Flow on LibriTTS dataset using a continuous mel-representation. Through our training method using continuous speech prompts, P-Flow matches the speaker similarity performance of the large-scale zero-shot TTS models with two orders of magnitude less training data and has more than 20x faster sampling speed. Our results show that P-Flow has better pronunciation and is preferred in human likeness and speaker similarity to its recent state-of-the-art counterparts, thus defining P-Flow as an attractive and desirable alternative.
The following are the key technical highlights of our work:
- We propose a speech prompt approach for the non-autoregressive zero-shot TTS model which surpasses the speaker embedding approach and provides in-context learning capabilities for speaker adaptation.
- We propose a flow matching generative model for a high-quality and fast zero-shot TTS that significantly improves the synthesis speed and sample quality compared to the large-scale autoregressive baseline.
- We demonstrate comparable speaker adaptation performance to the large-scale autoregressive baseline using significantly fewer training data and a small transformer-based encoder, highlighting the effectiveness of the proposed speech prompting approach.
- P-Flow achieves an average inference latency of 0.11 seconds on an NVIDIA A100 GPU.
This work is published at NeurIPS 2023.
The samples below are generated by a version of P-Flow that was trained on a larger amount of data and utilized a larger model architecture than what was presented in the paper. In the samples below we synthesize P-Flow’s abstract in English with different reference voices from our first and last authors.
| Reference Speaker | Reference | P-Flow (v1.5) |
|---|---|---|
| Bryan Catanzaro | ||
| Sungwon Kim | ||
| Sungwon Kim | ||
| Sungwon Kim | ||
| Sungwon Kim | ||
| Sungwon Kim |
Method
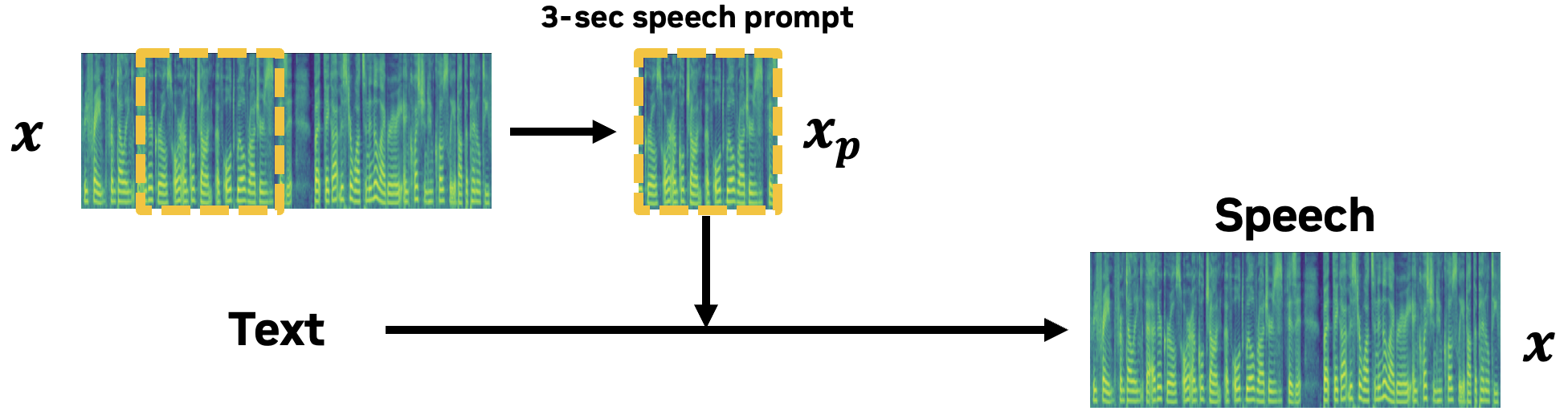
In this work, we aim to provide in-context learning capabilities for zero-shot speaker adaptation in a high-quality and fast non-autoregressive TTS model. To avoid the potential bottleneck of speaker embedding approaches to extract speaker information from the reference speech, we adopt a speech prompting approach that directly utilizes the reference speech as a prompt for speaker adaptation, similar to neural codec language models.
Given a <text, speech> paired data, P-Flow trains in a manner similar to a masked autoencoder, using a 3-second random segment of the speech data and the text input for generative modeling on the remaining segment. During zero-shot inference, P-Flow performs zero-shot TTS by providing a 3-second reference speech of the desired speaker as a prompt. P-Flow has the advantage of executing zero-shot TTS using only audio as a prompt, without the need for a transcript of the reference speech.
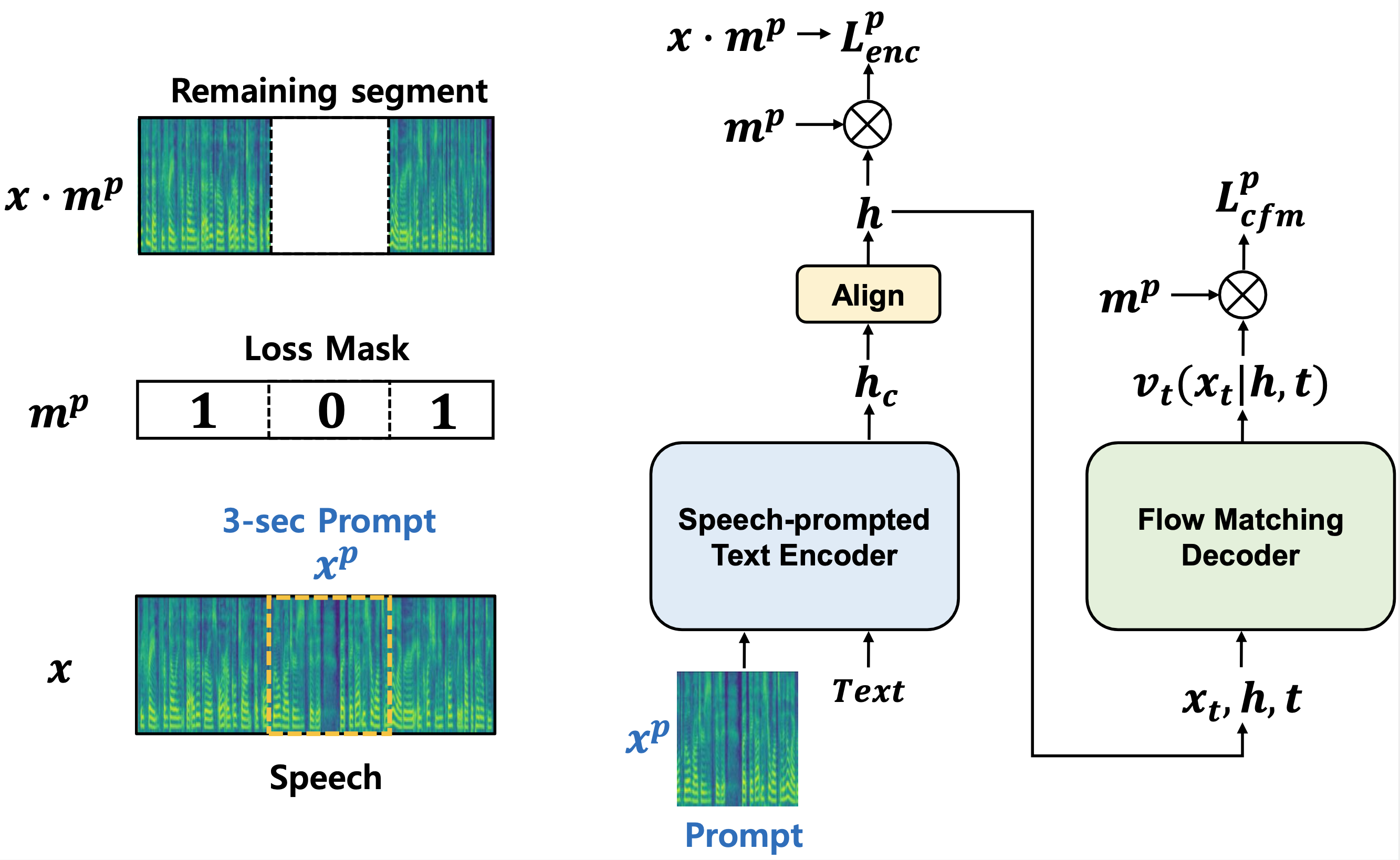
In P-Flow, we provide the text encoder with a mel-spectrogram of a 3-second reference speech as a speech prompt, along with the text input, to output a text representation for the reference speech. Additionally, we employ a new type of generative model, the flow-matching model, as a decoder for fast and high-quality speech synthesis.
- Speech prompted text encoder for speaker adaptation
- Flow matching generative model for fast and high-quality speech synthesis
Audio Samples
Section 4.1 - Prompting v.s. Separate Speaker Encoder
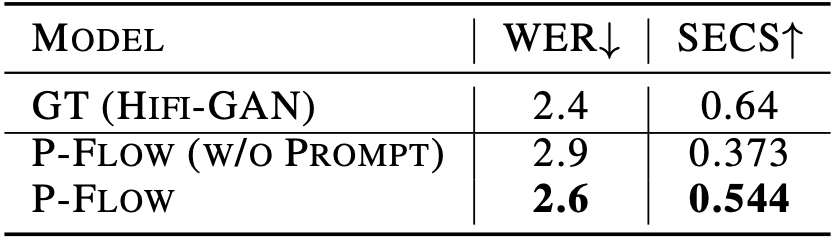
This result demonstrates the effectiveness of speaker conditioning through speech prompting. For the baseline (= P-Flow w/o Prompt), instead of directly inputting the speech prompt into the text encoder, we encode a random segment of speech to a fixed-size speaker embedding using a speaker encoder with the same architecture as the text encoder. The table below shows that even without changing other aspects, the use of speech prompts leads to a substantial enhancement in speaker similarity.
- P-Flow: Use Speech-prompted text encoder
- P-Flow (w/o Prompt): Use a fixed-size speaker embedding from a transformer-based speech encoder
| Reference | P-Flow | P-Flow (w/o Prompt) |
|---|---|---|
| They moved thereafter cautiously about the hut, groping before and about them to find something to show that Warrenton had fulfilled his mission. | ||
| Yea, his honourable worship is within. But he hath a godly minister or two with him, and likewise a leech. | ||
| The army found the people in poverty and left them in comparative wealth. | ||
| He was in deep converse with the clerk, and entered the hall holding him by the arm. | ||
Section 4.2 - Model Comparison (LibriSpeech)
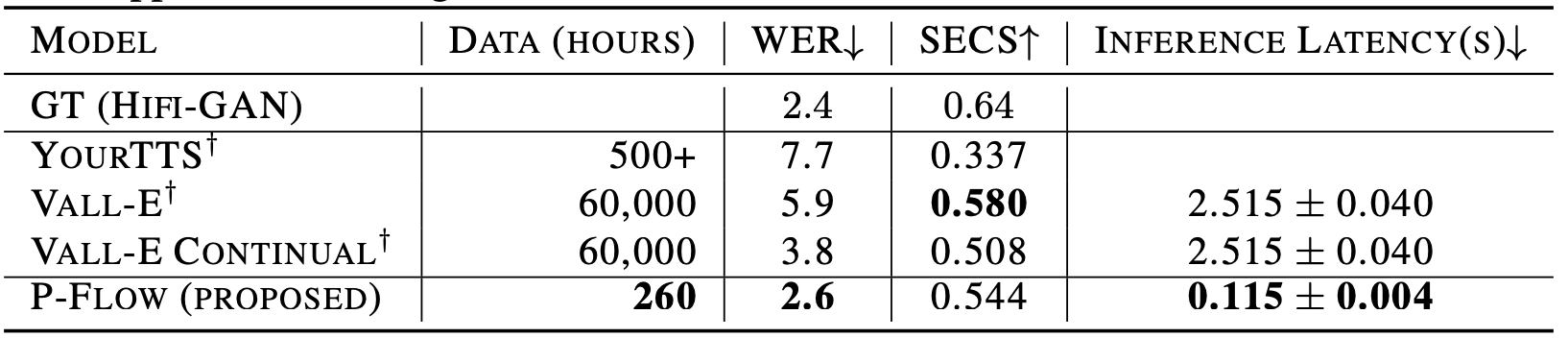
We compare P-Flow with state-of-the-art zero-shot TTS model, VALL-E. Although P-Flow is trained on significantly less amount of training data than VALL-E, P-Flow achieves better WER (ASR metric), comparable SECS (Speaker similarity metric), and 20 times faster sampling speed.
- Baseline: VALL-E
| Ground Truth | Reference | P-Flow | VALL-E |
|---|---|---|---|
| They moved thereafter cautiously about the hut, groping before and about them to find something to show that Warrenton had fulfilled his mission. | |||
| And lay me down in thy cold bed, and leave my shining lot. | |||
| Yea, his honourable worship is within. But he hath a godly minister or two with him, and likewise a leech. | |||
| Instead of shoes, the old man wore boots with turnover tops, and his blue coat had wide cuffs of gold braid. | |||
| The army found the people in poverty and left them in comparative wealth. | |||
| Thus did this humane and right-minded father comfort his unhappy daughter; and her mother, embracing her again, did all she could to soothe her feelings. | |||
| He was in deep converse with the clerk, and entered the hall holding him by the arm. | |||
Appendix - Model Comparison (VCTK)
We further compare the P-Flow model with the baseline VALL-E model on a subset of the VCTK dataset samples. Despite being trained on significantly less data compared to VALL-E, P-Flow demonstrates good speaker adaptation performance on the out-of-distribution VCTK dataset.
| Ground Truth | Reference | P-Flow | VALL-E |
|---|---|---|---|
| We have to reduce the number of plastic bags. | |||
| So what is the campaign about? | |||
| My life has changed a lot. | |||
| Nothing is yet confirmed. | |||
| I could hardly move for the next couple of days. | |||
| His son has been travelling with the Tartan Army for years. | |||
| Her husband was very concerned that it might be fatal. | |||
| We’ve made a couple of albums. | |||
Section 4.3 - Effect of Guidance Scale and Euler Steps
Effect of Guidance Scale (Gamma=Guidance Scale, N=10)
| Reference | P-Flow (Gamma=0) | P-Flow (Gamma=1) | P-Flow (Gamma=2) |
|---|---|---|---|
| They moved thereafter cautiously about the hut, groping before and about them to find something to show that Warrenton had fulfilled his mission. | |||
| Yea, his honourable worship is within. But he hath a godly minister or two with him, and likewise a leech. | |||
| The army found the people in poverty and left them in comparative wealth. | |||
| He was in deep converse with the clerk, and entered the hall holding him by the arm. | |||
Effect of Sampling Steps (N=Sampling Steps, Gamma=1)
| Reference | P-Flow (N=1) | P-Flow (N=2) | P-Flow (N=5) | P-Flow (N=10) | P-Flow (N=20) |
|---|---|---|---|---|---|
| They moved thereafter cautiously about the hut, groping before and about them to find something to show that Warrenton had fulfilled his mission. | |||||
| Yea, his honourable worship is within. But he hath a godly minister or two with him, and likewise a leech. | |||||
| The army found the people in poverty and left them in comparative wealth. | |||||
| He was in deep converse with the clerk, and entered the hall holding him by the arm. | |||||
Appendix - Zero-shot TTS with Emotional Reference Speech
Text: We have to reduce the number of plastic bags.
| Emotion | Reference | P-Flow | VALL-E |
|---|---|---|---|
| Anger | |||
| Sleepiness | |||
| Neutral | |||
| Amused | |||
| Disgust |